General-purpose world representation
OrbiSim adopts an asset-conditioned representation interface that supports heterogeneous object types through appropriate state and geometry encodings, rather than being limited to a task-specific design.
Project Page
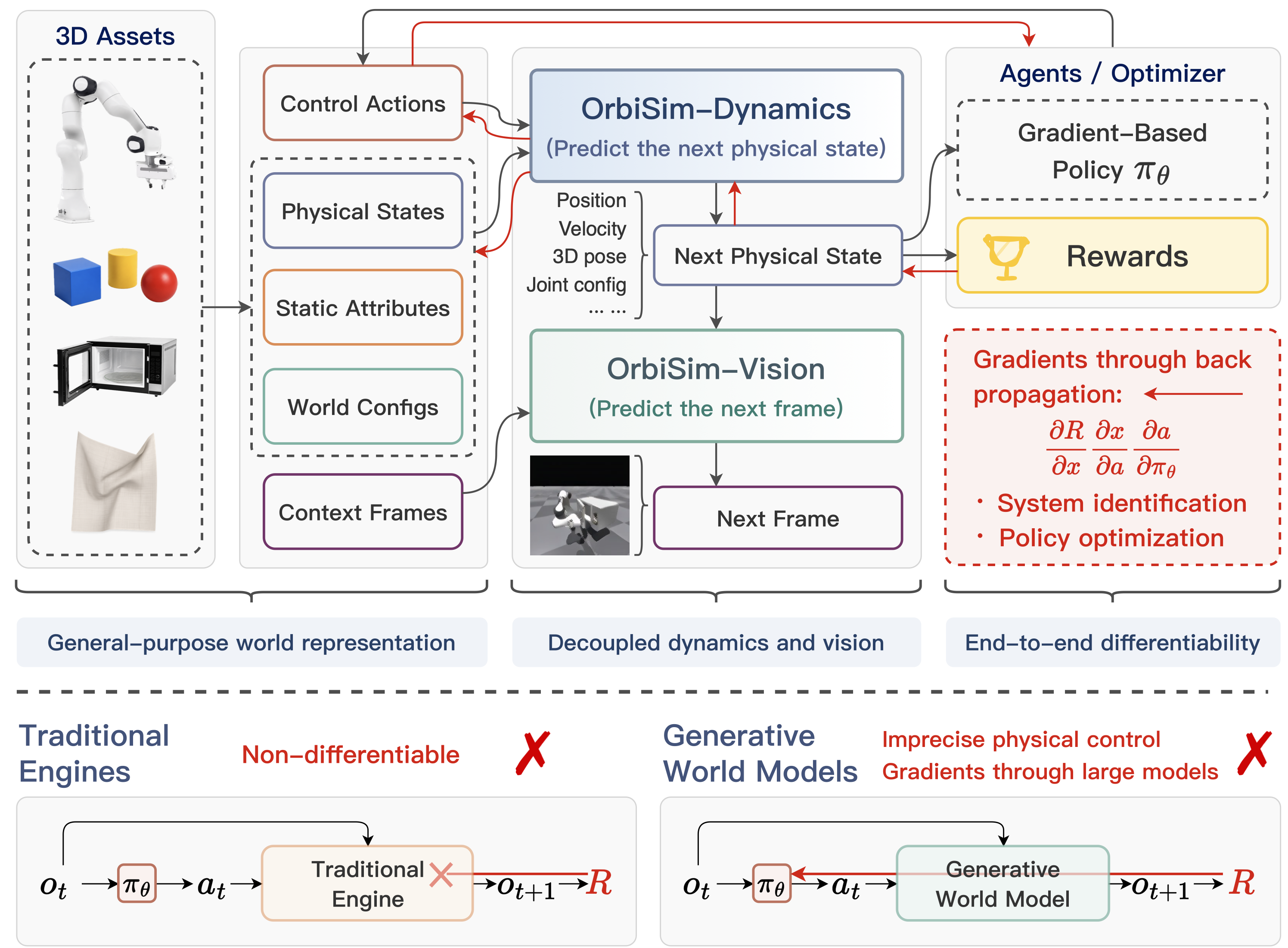
OrbiSim redefines world models as a differentiable physics engine that unifies structured scene assets, neural dynamics, visual prediction, and downstream control.
Code coming soon.
Abstract
We present OrbiSim, a novel robotic simulation paradigm that redefines world models as a fully differentiable physics engine for embodied intelligence. Unlike prior world models that focus on unconstrained imagination in latent or visual domains, OrbiSim establishes a unified, physically-grounded pathway that bridges structured scene assets, neural dynamics, and downstream reinforcement learning.
By enabling end-to-end differentiability throughout the entire simulation loop—spanning from explicit state transitions to visual observation generation—OrbiSim supports tasks traditionally intractable for classical simulators, such as differentiable contact modeling, gradient-based policy optimization under sparse rewards, and intuitive physical inference.
Empirical results demonstrate that OrbiSim significantly outperforms state-of-the-art world models in both predictive fidelity and control performance. Furthermore, its consistent responsiveness to asset configurations and physical parameters suggests its potential as a differentiable tool for enhancing robot simulation and policy training.
Overview
The model couples asset-conditioned dynamics with state-guided vision, enabling analytical gradients through the simulation loop for system identification and policy optimization.
Core Strengths
The architecture is built around a small set of principles that connect representation, prediction, and optimization in a single differentiable simulation pipeline.
OrbiSim adopts an asset-conditioned representation interface that supports heterogeneous object types through appropriate state and geometry encodings, rather than being limited to a task-specific design.
By decoupling the neural architecture into interlinked dynamics and rendering modules, OrbiSim simultaneously predicts precise physical states and high-fidelity visual observations and enables seamless integration with existing simulation platforms.
The differentiable pipeline facilitates Real-to-Sim system identification over scene parameters and gradient-based policy optimization for downstream control.
Experiments
We evaluate OrbiSim as both a generative world model and a differentiable execution engine, focusing on generative fidelity and physical consistency under varying configurations, as well as the benefits of differentiable gradient pathways for downstream reinforcement learning.
Generative and Physical Fidelity
As shown in Table 1, OrbiSim (Final) consistently achieves state-of-the-art performance across all metrics and horizons. Compared with AdaWorld and Vid2World, OrbiSim maintains superior temporal coherence and lower trajectory error, demonstrating a more robust alignment between physical dynamics and visual synthesis.
| Method | PSNR10 ↑ | PSNR100 ↑ | LPIPS10 ↓ | LPIPS100 ↓ | FVD ↓ | TrajErr ↓ |
|---|---|---|---|---|---|---|
| Vid2World | 22.2014 | 17.8856 | 0.1312 | 0.2551 | 1750.1 | 0.6754 |
| AdaWorld | 26.6647 | 12.8346 | 0.1183 | 0.3482 | 1305.8 | 1.8597 |
| Orbisim w/o Decoupling | 27.9346 | 19.9510 | 0.1188 | 0.1799 | 689.1 | 0.8134 |
| Orbisim w/o Random Sampling | 26.6890 | 19.1119 | 0.1076 | 0.1669 | 531.2 | 0.5742 |
| Orbisim w/o Object-Centric | 25.9373 | 19.7581 | 0.1123 | 0.1463 | 524.5 | 0.4687 |
| Orbisim (Final) | 26.7105 | 19.9819 | 0.1078 | 0.1428 | 533.9 | 0.4468 |
We report PSNR and LPIPS at different rollout horizons (10 / 100 steps), together with the overall FVD score. TrajErr measures the discrepancy between inferred physical states from generated videos and the corresponding true trajectories. All models perform autoregressive rollouts from shared initial states.
Qualitative Task Videos
We visualize four physics-rich settings used throughout the
paper: robotsuite Push
under varying friction, Isaac Lab
Stack, AdaManip
Articulated, and
Physion Drape.
Together, these
rollouts highlight sensitivity to physical parameters,
long-horizon stability, joint-constrained part motion, and
geometry-conditioned cloth deformation under the same
asset-conditioned simulation framework.
Push fixes
the same initial visual observation and replays the same
action sequence under different friction settings. OrbiSim
responds to the changed physical parameter with distinct,
physically consistent rollouts.
Stack
requires a Franka arm to sequentially stack three cubes,
demanding long-horizon stability and precise multi-object
interaction over 200+ simulation steps.
Articulated features
robot interaction with joint-constrained objects of diverse
shapes and mechanisms, testing whether the model can preserve
articulated part motion over autoregressive rollouts.
Drape
evaluates deformable cloth dynamics as a cloth falls onto
rigid objects with varying geometries, emphasizing
geometry-conditioned deformation under the same simulation
pipeline.
Downstream Control
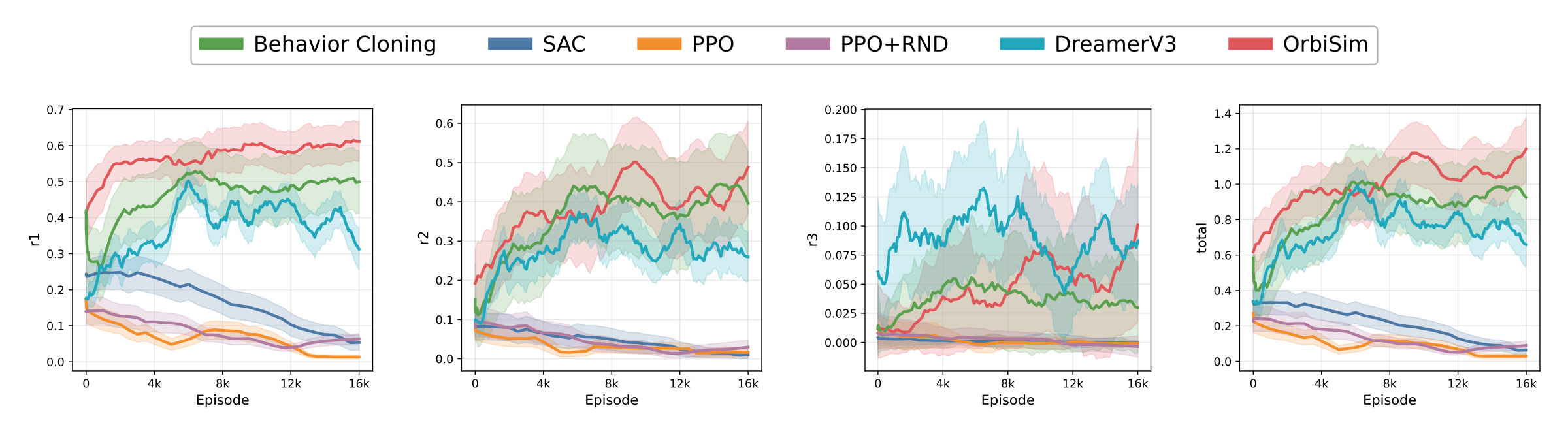
While the sparse episodic reward design makes credit assignment particularly challenging, OrbiSim differs from traditional black-box simulators by exposing analytical gradient pathways that propagate task-specific reward signals directly to the policy parameters. As shown in the training curves and rollout comparisons below, OrbiSim achieves superior performance and convergence speed compared with model-free, model-based, and imitation baselines.
Push task
In the robotsuite
Push task, the goal
is to push the first cube into the second one so that, after
the collision, the second cube comes to rest as close as
possible to the left table edge without falling off.
The reward is decomposed into three terms:
r1 encourages the end
effector to approach the first cube,
r2 encourages the first
cube to move into the second cube, and
r3 encourages the second
cube to settle near the left edge while remaining on the
table.
Push task
Policies trained with model-free RL fail to learn effective behaviors for the downstream task, while DreamerV3 and behavior cloning remain less stable under long-horizon interactions. In contrast, OrbiSim produces coherent and goal-directed behaviors across different scenarios.
Citation
@misc{li2026orbisimworldmodelsdifferentiable,
title={OrbiSim: World Models as Differentiable Physics Engines for Embodied Intelligence},
author={Jiajian Li and Jingyuan Huang and Junru Gong and Qi Wang and Xiaokang Yang and Yunbo Wang},
year={2026},
eprint={2605.16395},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2605.16395},
}